
Unterschleissheim, 22.07.2020 – Philosys Ground Truth Annotator 2020 - Semantic Segmentation 2D/3D
Ground Truth Annotator 2020 will support integrated 2D/3D segmentation with object data filters.
Introduction
Semantic Segmentation of data is getting more and more important. Up to now Ground Truth Annotator (GA) already supported 2D segmentation by SegmentationProvider.
With this provider plugin it is possible to segment regular images in relation to a single category, like the class of the object. This is also possible for multiple cameras concurrently, so that a complete surround view can be segmented within one project.
The result for each pixel is stored as base64 coded PNG images with color lookup table, and can also be exported as regular PNG images. These can then be easily used for machine learning and validation.
The old Segmentation Provider is deprecated now, but is still available to support older projects.
3D Semantic Segmentation
3D Semantic segmentation of lidar point clouds is getting also more common now. GA supported it for special projects with the help of the Generic Object Detector (GOD). Segmentation happens with the help of filter objects, which also allow for the use of interpolation. This saves considerably amount of work for segmentation of sequences.
To improve annotation efficiency futher this feature is now implemented within the new SemanticSegmentation3D plugin. It calculates the Semantic Segmentation result dynamically in real-time, so that the annotator immediately sees the result of his actions.
Semantic Segmentation Integration 2D/3D
All has now be integrated into one user interface for both 2D/3D. The SegmentationGUI has been taken from the SegmentationProvider and now controls both 2D and 3D Semantic segmentation, implemented by the new SemanticSegmentation2D and SemanticSegmentation3D plugins.
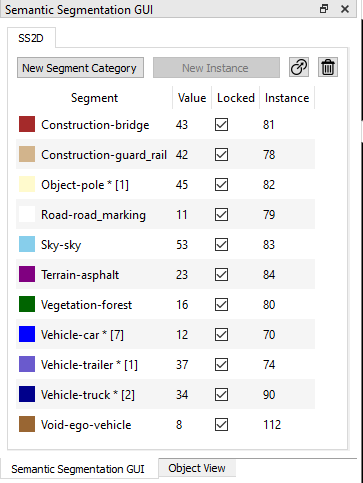
Annotation starts with an empty segment list. Depending on configuration, segmentation categories can have instances or not. After creation of a segment with the selected category value, labeling can be started either with 2D image or 3D point cloud.
A new instance of a category value can be created with the "New Instance" button. Additional buttons allow the change of the category value and deletion of an instance.
All information about the categories and the instances is stored in the internal object tree. Each instance is represented by an object and can be viewed with ObjectView. But normally everthing can be handled just with the SemanticSegmentationGUI.
The label object is the common part between 2D and 3D Semantic Segmentation. If annotation starts within 2D, labeling the same object in 3D is as easy as selecting the object in 2D image, switching to 3D view and using the selected object to label the 3D object. When finished, the same objects in 2D and 3D have the same category value and instance.
Semantic Segmentation 2D
Note: The following example data set has only a front camera, Therefor 3D Semantic Segmentation is only be done in part.
GA provides through its window manager a very flexible way to setup the user interface for labeling. The following image shows an example for a 2D labeling setup.
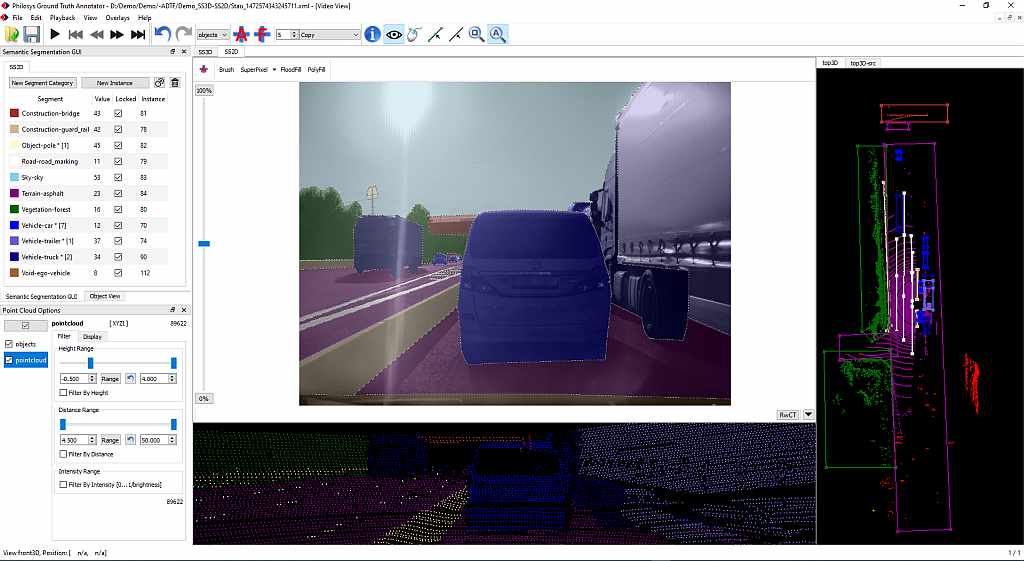
It provides all information regarding the combined 2D/3D project and allows also to review the state of all objects.
At the left there are the SegmentationGUI the the Point Cloud Options located. In the top center there is the 2D segmentation area, with the possibility to select a tool for segmentation.
Below you see the segmented point cloud from the perspective of the lidar scanner.
At the right side you see the top view of the segmented lidar data with the filter objects.
Of course, a pure 2D segmentation view can also be configured to have more screen space available. Tabs and the thumbnails on top row can be used to switch between different views.
Semantic Segmentation 3D
For the 3D Semantic Segmentation the following view may be helpful:
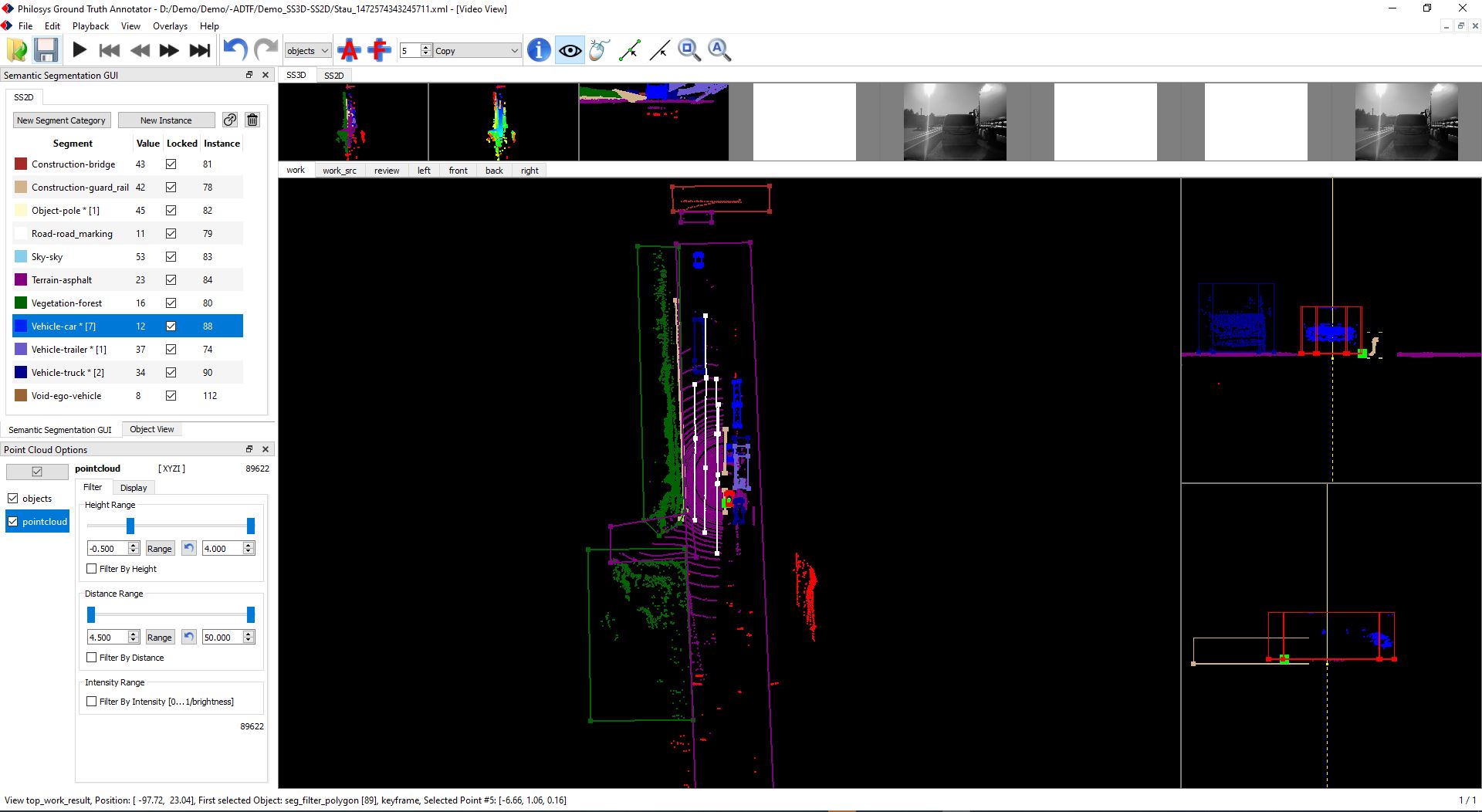
Here the center contains the top view with filter objects and at the right side there a side views of the currently selected object. The latter can be used to place and resize the filter object at the correct position.
Object detection with the Generic Object Detector (GOD) can be used to automate object extraction with hull, base position and height for filter objects.
Resulting Data



Summary
- Support of both 2D and 3D Segmentation
- Common GUI for better usability and consistent labeling
- Instances are the same for same object in 2D and 3D
- Filter objects allow easy point cloud segmentation
- Filter objects can be sized with the help of generic object detector.
- Point Cloud can be filtered and colored for better data selection
- Filter objects allow use of interpolation in data sequences
- Flexible window setup with easy switch
- Adaptable to annotation requirements
All this points help to achieve a very high annotation efficiency.
Further Information
A short description of the most recent features can be found at the following links:
Philosys Ground Truth Annotator 2020 - Preview
Philosys Ground Trutz Annotator 2019
Philosys Labeling in the Cloud
Philosys Ground Truth Annotator
Philosys Ground Truth Annotator 2018
Philosys Label Editor Version 6 - Semantic Segmentation
Philosys Label Editor Version 6 - Release 6.3.2
Philosys Label Editor Version 6 - Release 6.2
Philosys Label Editor Version 6 - Release 6.1
Philosys Label Editor Version 5 - Release 5.1
The Philosys Label Editor and also the Philosys Ground Truth Annotator are used during development and test of diverse Advanced Driver Assistance Systems (ADAS) for ground truth data annotation/labeling. Objects are manually or automatically marked and tagged with detailed traits. All kinds of vehicles, lane boundaries, traffic signs as well as pedestrians and wildlife animals are registered and verified by the assistance system for use during validation, and the data can be used for generating reference data for deep neural network (DNN) maschine learning and validation.
The ADTF based Philosys Label Editor is available as of the beginning of 2011, and the ADTF-free Philosys Ground Truth Annotator is available since mid-2018. Their many features facilitate the annotation of video scenes and reference data. This results in a significant cost reduction for the annotation process.
Ende 2012 wird der neue Philosys Label Editor Version 2 erscheinen. Dieser enthält eine Vielzahl von neuen Features, die nicht nur den Prozess der Annotation beschleunigen, sondern auch neue Anwendungsgebiete erschließen.
- Integration externer Referenzdaten
- Interpolation
- Geometrisches Objekt Polygon
- Projektmodus
Die folgenden Kapitel geben eine Übersicht über die Funktionalität und Anwendung der neuen Funktionen.
Integration externer Referenzdaten
Zur Validierung komplexerer Assistenzsysteme werden neben der reinen Position des Objektes auf dem Videobild, und einfachen durch den Annotator aus dem Videobild zu bestimmender Attributen, oft auch Daten benötigt, die aus anderen Quellen als dem Videobild kommen. Dies sind neben bestimmten CAN-Daten für das eigene Fahrzeug, oft auch Daten von Sensoren, die nur in den Fahrzeugen für die Aufzeichnung verbaut werden. Dies können unter anderem z. B. objektbildende Laserscanner sein. Diese erkennen wie das zu testende Assistenzsystem ebenfalls Objekte und können eine Reihe von nützlichen Daten, wie die Entfernung zum jeweiligen Objekt, relative Geschwindigkeit, usw., bereitstellen.
Interessant sind hier die Daten die der Annotator nicht so einfach selbst bestimmen kann, wie die Entfernung zum Objekt und dessen relative Geschwindigkeit. Anstatt diese Referenzdaten alle manuell von der Laserscanner Software in die Annotationsdaten zu übernehmen, bietet es sich hier an diese Aufgabe direkt mit Hilfe des Labeleditors zu erledigen.
Notwenig ist dazu dass die Sensordaten zeitsynchron zusammen mit den Videodaten aufgezeichnet werden. Die Umwandlung der Sensordaten in das Format das der Philosys Labeleditor versteht, erfolgt dann mit Hilfe eines neu zu erstellenden Decoder-Filters, der in Filtergraph, der das Video für den Labeleditor aufbereitet, integriert wird. Die Schnittstelle des Labeleditors für externe Referenzdaten ist XML. Diese Daten sind im Prinzip genauso aufgebaut wie das Ergebnis der Annotation, die Labeldaten. Sie müssen auch wie die Labeldaten in der Strukturdatei beschrieben werden.
Wurde die Struktur der externen Referenzdaten beschrieben, und von dem Filter die gewünschten Referenzdaten in dieses Format konvertiert, dann kann der Philosys Labeleditor diese Daten im Detail im ObjectView darstellen. Wenn in den Daten auch geometrische Objekte vorhanden sind, dann werden diese auch im VideoView angezeigt. Es gibt dann einmal die Möglichkeit bestimmte in der Strukturdefinition beschriebene Datenelemente einfach in ein gerade aktives Annotationsobjekt für das aktuelle Frame zu übernehmen. Oder aber man kann einen Link zwischen Referenzobjekt und Annotationsobjekt herstellen, womit dann die entsprechenden Datenelemente für alle Frames in denen das Referenzobjekt und das Annotationsobjekt existieren, übernommen werden. Dies reduziert den Aufwand für die Übernahme erheblich. Das Feature funktioniert auch zusammen mit der Interpolation. Existieren Referenzdaten zu einem interpolierten Frame so werden die Referenzdaten verwendet, so dass die Genauigkeit der Referenzdaten erhalten bleibt.
Dieses neue Feature ist der Einstig in die 3D-Annotation für Videodaten mit dem Philosys Labeleditor. Dabei kann so wie bisher das jeweilige Objekt vom Annotator auf dem Bild markiert, zusätzlich können aber noch die Entfernung und andere relevante Daten mit Hilfe der Referenzdaten automatisch gesetzt werden.
Durch die offene Schnittstelle kann der Kunde den nötigen Filter für die Wandlung der Referenzdaten in XML selbst implementieren. Er kann aber auch die Erfahrung von Philosys nutzen und den Decoder-Filter von Philosys erstellen lassen.
Interpolation
Das Annotieren ist ein zeitaufwendiger Prozess. Der Zeitaufwand pro Videominute kann je nach Komplexität mehr als das Hundertfache der Videolaufzeit betragen. Durch das Feature vorhandene Daten jeweils in das nächste Bild zu übernehmen, und die Position geometrischer Objekte dabei auch noch zu Extrapolieren, beschleunigt schon der bisherige Philosys Label Editor das Annotieren gegenüber herkömmlichen Verfahren erheblich.
Durch das neue Feature Interpolation wird die Annotationszeit jetzt in Fällen, wo Objekte sich über viele Frames hinweg kaum in ihrer Position verändern, nochmal deutlich verkürzt. Man markiert wie gewohnt am Anfang der Sichtbarkeit das Objekt auf dem Videobild mit einem beliebigen geometrischen Objekt, und setzt dieses über das per rechten Mausklick erscheinende Kontextmenü als Startbild für die Interpolation. Dann geht man zu dem Bild, an dem man das Objekt normalerweise zuletzt markieren würde, markiert dieses und setzt dieses als Endbild für die Interpolation. Jetzt wird für alle Bilder zwischen Start- und Endbild das geometrische Objekt interpoliert. Die anderen Attribute werden automatisch vom Zustand im Startbild übernommen. Gibt es im interpolierten Bereich eine Abweichung, so kann man an der entsprechenden Position einfach durch anklicken und Repositionierung des interpolierten geometrischen Objektes einen neuen Stützpunkt erzeugen. Die Interpolation wird dann automatisch vor und hinter dem Stützpunkt neu berechnet. Idealerweise setzt man einen neuen Stützpunkt dort wo die Abweichung am größten ist. In vielen Fällen reichen dann wenige Stützpunkte für eine hinreichend genaue Übereinstimmung aus.
Derzeit wird linear interpoliert, das kann aber erweitert werden. Denkbar ist auch eine zukünftige Erweiterung mit einem Tracker.
Als Nebeneffekt reduziert sich auch der Hauptspeicherbedarf bei Szenen mit langer Objektsichtbarkeit deutlich. Natürlich werden zur Gewährleistung der Kompatibilität in der Toolkette wie bisher die Daten für alle Bilder geschrieben.
Geometrisches Objekt Polygon
Um auch unregelmäßige Objekte effizient markieren zu können, wird der Philosys Label Editor um das neue geometrische Objekt Polygon erweitert. Das Polygon wird wie die anderen geometrischen Objekte am einfachsten mit der Maus erstellt. Es gibt dabei die Möglichkeit sowohl einen offenen Linienzug oder ein geschlossenes Polygon zu erzeugen. Der Typ kann auch nachträglich geändert werden.
Wie gewohnt kann man das Polygon über das mit der rechten Maustaste erscheinende Kontextmenü in der in der Struktur-XML vordefinierten Form an der Mausposition erzeugen. Danach kann man durch Neupositionierung der Maus und der linken Maustaste weitere Linien an ein offenes Polygon anhängen. Man kann auf Linien weitere Eckpunkte einfügen und natürlich Punkte, Linien und das gesamte Polygon verschieben. Natürlich funktioniert mit dem Polygon auch die hilfreiche Extrapolation beim automatischen Übertrag von einem Bild zum Nächsten.
Mit dem Polygon kann man nicht nur unregelmäßige Objekte markieren, sondern mit seiner offenen Form auch als Linienzug nutzen. Damit ist es z. B. auch möglich Spuren genauer und einfacher zu markieren.
Projektmodus
Der Projektmodus erlaubt es die für die Annotation nötigen Dateien mit einem Befehl zu laden. Dazu packt man den Filtergraph, die Strukturdatei, die DAT-Datei und die Annotationsdatei in ein Verzeichnis. Die Generierung des Inhalts kann dann durch ein entsprechendes Szenenmanagement-system geschehen.
Damit ist es jetzt einfach möglich ohne komplizierte Namenstransformationen mit mehreren Kameras aufgezeichnete Szenen für verschiedene Projekte individuell zu annotieren. Zu dem erleichtert es die Arbeit der Annotatoren und vermeidet fehlerhafte Namen beim Abspeichern der Daten.
Der Philosys Label Editor wird bei der Entwicklung unterschiedlichster Assistenzsysteme zur Gewinnung von Ground-Truth-Daten eingesetzt. Dabei werden die verschiedensten Objekte markiert und mit detaillierten Attributen versehen. Angefangen von Fahrzeugen aller Art, Fahrbahnbegrenzungen, Verkehrszeichen, bis hin zu Fußgängern und Wildtieren. Die erfassten Daten werden anschließend zur Verifizierung der von Assistenzsystemen erkannten Objekte verwendet.